§ 13. кодирование текстовых данных
| 13.1. Представление текста
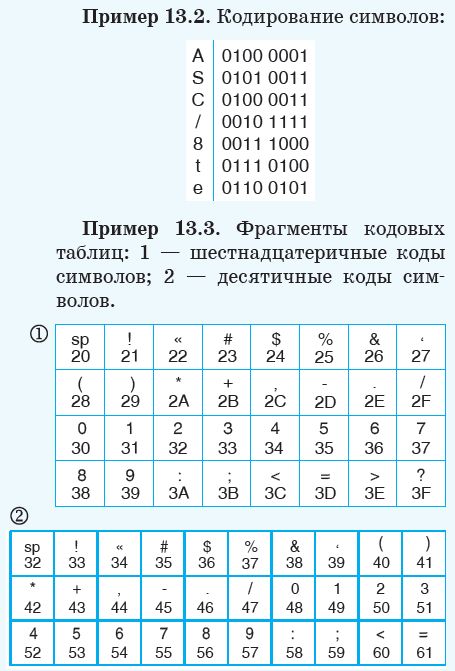
Естественной для органов чувств человека является аналоговая форма представления информации, однако дискретная форма представления с помощью некоторого набора знаков наиболее универсальная. Для записи текста используют символы алфавита (пример 13.1). Представление информации в алфавитной (текстовой) форме — самый распространенный способ со времен изобретения письменности. Информация передается в виде текста, записанного на каком-либо языке: русском, белорусском и т. д. Для записи текста на разных языках можно использовать один алфавит. Например, для записи текста на русском или белорусском языках используют кириллицу, а для записи текста на английском или немецком языках — латиницу. Для записи текста в память компьютера используют двоичный код — алфавит из двух символов: 0 и 1. 13.2. Понятие кодовой таблицы Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Множество этих символов образуют компьютерный алфавит. Текст, состоящий из данных символов, человек видит на экране монитора. Компьютер может обрабатывать информацию только в числовой форме, представленной в виде двоичного кода. Поэтому для кодирования текста каждому символу алфавита ставят в соответствие двоичный код (пример 13.2). Часто всем знакам алфавита ставятся в соответствие коды, содержащие одинаковое число двоичных разрядов.
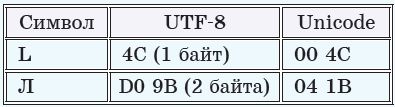
С помощью кодовых таблиц выполняют кодирование и декодирование текста. Часто для удобства пользователя в кодовых таблицах вместо двоичного кода записывается его десятичный или шестнадцатеричный аналог (пример 13.3). Для получения двоичного кода (из десятичного или шестнадцатеричного) нужно осуществить перевод числа в двоичную систему счисления. Для разных компьютерных систем могут использоваться различные кодовые таблицы символов. В разных кодовых таблицах одним и тем же символам ставится в соответствие разный двоичный код (пример 13.4). В этом случае текст, созданный на одном компьютере, нельзя будет прочитать на другом компьютере без дополнительного перекодирования — символы будут отображаться некорректно (пример 13.5). Международным стандартом стала таблица кодировки ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией). Данная таблица поддерживает 8-разрядный двоичный код. Это значит, что каждый символ будет закодирован последовательностью из 8 нулей и единиц. Такая последовательность и будет кодом символа. Всего в таблице 28 = 256 символов. Так как каждый символ кодируют последовательностью из 8 нулей и единиц, он занимает в памяти компьютера 8 бит (1 байт). В примерах 13.6—13.9 показано, как с помощью таблицы символов ASCII (см. Приложение к главе 2, с. 118—119) кодировать и декодировать символы. В таблице ASCII символы латинского и русского алфавитов (прописные и строчные) идут по алфавиту. Десятичные цифры расположены в порядке возрастания их числовых значений. Это правило обычно соблюдается и в других кодовых таблицах. Такой способ кодирования текста позволяет сортировать текстовые данные по алфавиту, а числовые — по возрастанию их значений. В кодовой таблице ASCII хранится 256 символов. Если нужно работать с текстами сразу на нескольких языках, то этих символов недостаточно. Сейчас широко используют кодировку Unicode (Юникод). В ней компьютерный алфавит состоит не из 256, а из 65 536 символов. Для кодирования одного символа используется последовательность из 0 и 1, имеющая длину 16 символов. При такой кодировке каждый символ будет занимать в памяти компьютера 2 байта. Просмотреть кодовую таблицу на вашем компьютере можно запустив программу Таблица символов (находится в разделе Стандартные Служебные Таблица символов). Для определения кода символа нужно выбрать этот символ в таблице (пример 13.10). На всплывающей подсказке и в нижней части окна будет указан код символа в шестнадцатеричной системе счисления и название данного символа (на английском языке). Для поиска символа, соответствующего какому-либо коду, нужно ввести шестнадцатеричный код символа в поле Поиск. В выпадающем списке Набор символов можно выбрать определенный алфавит. Стандартная часть кодовой таблицы ASCII совпадает с началом таблицы кодировки Unicode. Поэтому тексты, содержащие символы, которые расположены в стандартной части кодовой таблицы ASCII (цифры, буквы английского алфавита), будут без труда читаться и в кодировке Unicode. Русские символы в таблице ASCII имеют коды, начиная с числа 8016 = = 12810, а в таблице Unicode — с шестнадцатеричного числа 0410 (код прописной буквы А). Тексты на русском языке, набранные в кодировке ASCII, будут неверно отображаться при просмотре в Unicode (пример 13.11). Для правильного просмотра текст необходимо преобразовать. Распространена кодировка UTF-8 (англ. Unicode Transformation Format, 8-bit — формат преобразования Юникода, 8 бит). Она позволяет более компактно хранить и передавать символы, используя переменное количество байт (от 1 до 4) для кодирования. Стандарт UTF-8 сейчас является самым распространенным в Интернете. Латинские буквы, цифры и наиболее распространенные знаки препинания кодируются в UTF-8 одним байтом, и коды этих символов соответствуют их кодам в ASCII. Кириллические символы кодируются двумя байтами (пример 13.12). Структуру двоичного кода символа в кодировке UTF-8 можно посмотреть в Приложении к главе 2 (с. 117). Тексты вводятся в память компьютера в основном с помощью клавиатуры. На клавишах написаны знакомые нам буквы, цифры, знаки препинания и другие символы. Нажатие на определенную клавишу кодирует символ, и в памяти компьютера он хранится в форме двоичного кода. При выводе символа на экран монитора внешний вид символа восстанавливается по его двоичному коду. Кодирование и декодирование текстовых данных происходит также при записи текста в файл на компьютерный носитель и при считывании текста из файла (пример 13.13). Информационный объем текста зависит от количества символов в нем и способа кодирования символов. Информационный вес одного символа равен 1 байту при использовании однобайтных (8-битных) кодовых таблиц и 2 байтам при использовании таблицы Unicode. При использовании таблицы UTF-8 информационный вес одного символа может составлять от 1 до 4 байт. 13.3. Решение задач на кодирование текста Пример 13.14. Определить информационный объем следующего предложения, если его закодировали с помощью кодовой таблицы Unicode: Программирование — вторая грамотность. Пример 13.15. Автоматическое устройство осуществило перекодировку сообщения из кодировки Unicode в кодировку ASCII. При этом информационный объем сообщения уменьшился на 12 байт. Сколько бит было в первоначальном сообщении? Пример 13.16. Информационный объем сообщения 8,5 Кбайт. Данное сообщение содержит 8704 символа. Какое максимально возможное количество символов содержится в алфавите? Пример 13.17*. Автоматическое устройство осуществило перекодировку сообщения, содержащего символы русского и латинского алфавитов из кодировки UTF-8 в 16-битный Unicode. (Символы латинского алфавита кодируются одним байтом, а русского — двумя байтами.) В результате преобразования сообщение стало занимать 21 Кбайт вместо первоначальных 15 Кбайт. Сколько в сообщении символов русского алфавита? Пример 13.18. Текст рассказа занимает 80 Кбайт. На одной странице 30 строк по 45 символов. Каждый символ кодируется 16 битами в формате Unicode. Сколько страниц в рассказе? |
|




1. Что такое алфавит? 2. Как кодируются символы? 3. Чем отличается кодирование текста при использовании разных кодовых таблиц? 4. Как определить код символа в приложении Таблица символов?
Упражнения
1. Используя кодовую таблицу ASCII или Unicode (программа Таблица символов), закодируйте следующие текстовые данные:
| Файл | Байт |
| Кодирование | Disk |
| Printer | Bit |
| Система счисления |
2. Декодируйте двоичный код, используя кодовую таблицу ASCII.
11101000 10101010 10101110 10101011 10100000
3. Декодируйте информацию, используя таблицу ASCII.
172 174 164 165 172 (десятичные числа).
E1 AA A0 AD E0 (шестнадцатеричные числа).
4. Используя программу Таблица символов, определите коды символов 1/2, ±, $, Щ, Ў.
5. Определите информационный объем сообщения «Участник олимпиады может писать программы на языках программирования Pascal, Python или С++».
1.В кодировке ASCII.
2.В кодировке Unicode.
3*.В кодировке UTF-8.
6. Сообщение, информационной объем которого в 16-битной кодировке равен 480 байт, перекодировали в 8-битную кодировку. После этого к сообщению дописали несколько символов, и его информационный объем стал равен 520 байт. Сколько символов дописали в сообщение?
7. Алфавит племени Тумба-Юмба состоит из 8 букв. Каков информационный объем одной буквы?
8. Сообщение, записанное буквами из 16-буквенного алфавита, содержит 21 символ. Каков информационный объем сообщения?
9. Статья, набранная на компьютере, содержит 6 страниц. На каждой странице одинаковое количество строк по 56 символов в строке. Информационный объем статьи 504 Кбит. Определите количество строк на каждой странице текста, считая, что каждый символ закодирован с использованием Unicode.
10. Скорость чтения учащегося 10-го класса составляет в среднем 1024 символа в минуту. Какой информационный объем получит учащийся, если будет непрерывно читать в течение 30 мин текст, набранный на компьютере в кодировке Unicode?
11. Для получения годовой отметки по географии учащемуся требовалось написать реферат на 15 страниц. Он выполнил это задание на компьютере, набирая текст в кодировке Unicode. Какой объем памяти (в Кбайтах) займет реферат, если в каждой строке по 72 символа, а на каждой странице помещается 28 строк? Каждый символ занимает 2 байта памяти.
12. Оцените информационный объем страницы текста из учебного пособия по информатике. Для этого посчитайте количество строк на странице и количество символов в строке. Для текста на белом и голубом фоне расчеты нужно проводить раздельно, а затем суммировать результаты. Текст набран с использованием кодировки Unicode.
13. Петя и Вася пишут друг другу письма, кодируя информацию следующим образом: каждый символ письма кодируется двоичным кодом по таблице ASCII. Затем 0 за¬меняется на 1, а 1 на 0. По полученным кодам в таблице отыскиваются символы, из которых складывается текст письма. Получивший письмо производит те же действия для того, чтобы письмо прочитать. Например, для кодирования слова «Привет» нужно поступить так:
С помощью программы калькулятор можно не только переводить числа в двоичную систему счисления, но и производить замену 0 на 1, а 1 на 0. Чтобы заменить 0 на 1, а 1 на 0 на калькуляторе (в режиме программист), нужно выполнить действие Xor над двумя двоичными числами: исходным числом и числом 11111111 (например, 10001111 Xor 11111111 = 1110000).
Закодируйте этим способом: Привет, Вася! Как дела?![]()
14. Для секретной переписки Оля и Света придумали свою кодовую таблицу. Декодируйте сообщение от Оли к Свете, используя часть таблицы. Придумайте коды для других букв русского алфавита.
15. Подтвердите или опровергните утверждение «СМС-сообщение, набранное транслитом, будет стоить дешевле, чем аналогичное сообщение, набранное русскими буквами».